Understanding the Hardware Behind AI Models
Events Deputy at IEEE WIE CEG
Abstract
In the era of powerful AI and ML models solving real-world problems, we need equally powerful chips to do billions of computations every second. This article explores the highly promising technology to run computationally complex, time-consuming AI and ML models and the challenges to address them.
Parallel Computing
Parallel computing is a process where large computation problems are broken down into smaller problems that can be solved simultaneously by multiple processors. During the late 1940s and 1950s, software was programmed to solve problems in sequence, which restricted processing speed. Parallel computing, employing multi-core processors and graphics processing units (GPUs), can be utilized to solve the computations at hand with greater ease.
Need for Parallel Computing
Parallel computing plays a critical role in the training of ML models for AI applications, such as facial recognition and natural language processing (NLP). By performing operations simultaneously, parallel computing significantly reduces the time that it takes to train ML models accurately on data. Here the workload is shared by CPU and GPU, the former does the preprocessing tasks and the later computed matrix multiplication, backpropagation etc., thereby completing the task at hand efficiently.
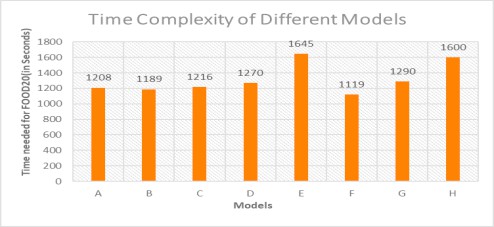
To highlight the computational complexities of CNN, the study "Time complexity in deep learning models" experimented with various CNN models to understand the time complexity of the model. They found significant variations in processing time across different model architectures.
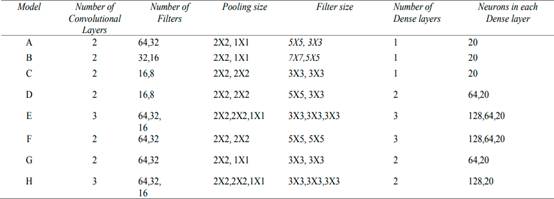
The dataset considered for the experiments is FOOD20. FOOD20 is the Indian food dataset provided by Kaggle that contains 20 food classes containing a total of 2000 images. 80% of the images from the dataset have been used for training and 20% of the images have been used for testing. The chosen parameters for the work are the number of convolution layers, number of dense layers, pool size, size of filters, size of neurons, number of filters, and size of the convolution kernel.
Specifications of various CNN models and their time complexity analysis.
In many Deep Neural Network (DNN) models, multiply-accumulate (MAC) operations are the main computations that need to be done. Consequently, hardware architectures capable of efficiently executing parallel MAC operations are essential for running DNN models at scale.
Overview of GPU Architecture and Its Role in Training AI Models
At a fundamental level, modern Graphics Processing Units (GPUs) are designed to implement massive parallel computation. Every GPU contains numerous parallel processing clusters, named Streaming Multiprocessors (SMs) in NVIDIA designs, Compute Units (CUs) in AMD products, and Xe Cores in Intel, each comprising multiple arithmetic logic units, dedicated registers for rapid data access, and shared local memory.
These clusters interface with the memory hierarchy, which typically includes L1 and L2 caches situated between the processing elements and the global memory (VRAM), which is based on high-speed High Bandwidth Memory (HBM) technologies. Specialized functional units such as tensor processing cores, ray tracing accelerators, and texture mapping units address the domain-specific computational demands.
 Modern GPU architecture with parallel processing clusters optimized for AI and ML workloads.
Modern GPU architecture with parallel processing clusters optimized for AI and ML workloads.
These clusters interface with the memory hierarchy, which typically includes L1 and L2 caches situated between the processing elements and the global memory (VRAM), which is based on high-speed High Bandwidth Memory (HBM) technologies. Specialized functional units such as tensor processing cores, ray tracing accelerators, and texture mapping units address the domain-specific computational demands.
An AI model can be viewed as a mathematical model to do the intended task, built from successive layers of linear algebra operations. GPUs contain thousands of processing cores capable of executing these operations simultaneously. GPUs are perfect fit to run these models as they are equipped with a massive amount of parallelism and specialized cores to match the demands of the required computations.
These clusters interface with the memory hierarchy, which typically includes L1 and L2 caches situated between the processing elements and the global memory (VRAM), which is based on high-speed High Bandwidth Memory (HBM) technologies. Specialized functional units such as tensor processing cores, ray tracing accelerators, and texture mapping units address the domain-specific computational demands. While this foundational architecture remains consistent across the industry, each vendor implements distinct optimizations to address its strategic priorities.
As generations pass, GPUs have incorporated larger memory capacities and refined memory management techniques, enabling entire AI models to be stored within a single GPU or across a coordinated set of GPUs, further improving performance and scalability.
Challenges
Despite rapid advancements, several challenges persist as AI models continue to grow in scale and complexity:
- Scalability remains a concern, as training large models often requires multi-GPU systems
- Memory bandwidth and capacity limitations pose significant hurdles, with many large-scale models exceeding the on-board memory of GPUs
- Energy efficiency and thermal management are important issues, as high-performance GPUs consume substantial power
- The high cost of state-of-the-art GPUs creates accessibility barriers, particularly for smaller research teams and independent developers
Conclusion
GPUs have established themselves as the backbone of modern AI and ML workloads, delivering massive parallel processing capabilities and integrating specialized compute units to meet the demands of increasingly complex models.
Their architectural evolution, driven by larger memory capacities, faster interconnects, and innovative processing clusters, has significantly expanded the possibilities for deep learning applications. Continued innovation in both hardware design and AI algorithms will determine how effectively the next generation of models can be trained and deployed.
References
- Shah, B., & Bhavsar, H. (2023). "Time Complexity in Deep Learning Models"
- NVIDIA: Why GPUs are Great for AI
- IBM. (2023). "Parallel Computing"
- Dhilleswararao, P., et al. (2022). "Efficient Hardware Architectures for Accelerating Deep Neural Networks: Survey" in IEEE Access, vol. 10, pp. 131788-131828
- NVIDIA Deep Learning Performance Documentation
Anisa Mariyam
Events Deputy at IEEE WIE CEG
Passionate about technology and research, contributing valuable insights to the IEEE WIE-CEG community.
More Articles
AI Co-Designers: How Machines Are Reshaping the Creative Process
Exploring how AI tools like ChatGPT, Midjourney, and Sora are transforming creative workflows, blurring the line between human inspiration and machine intelligence in art, music, code, and storytelling.
Bias Toward Simplicity in Code-Generating LLMs: An Empirical Evaluation of Algorithmic Reasoning Depth
This study investigates whether LLMs exhibit a bias toward simpler, suboptimal algorithms, even when more efficient or theoretically sound solutions exist. Through empirical evaluation of state-of-the-art LLMs across various algorithmic tasks, we reveal consistent preferences for naive solutions.
Explore More Research
Discover more cutting-edge research and insights from our talented club members.